The 3 + 1 pillars of data science
My student’s question…
A few weeks ago, one of my students posed a question I wasn’t expecting:
“Ahmed, what are the three core things I need to learn to become a data scientist?”
My first instinct was to say: if it were really just three things, I probably wouldn’t be here. But the question stuck with me, and after some thought I landed on three things that genuinely are foundational — plus one more I couldn’t leave out.
1-Derivatives
I don’t mean just taking derivatives on a calculus exam. I mean understanding what a derivative is as a concept: the rate of change of one thing with respect to another. Once that clicks, a surprising number of machine learning ideas become much clearer.
In linear regression, the coefficient \(\beta\) is literally a derivative — it tells you how much the expected value of \(y\) changes for a one-unit increase in \(x\).
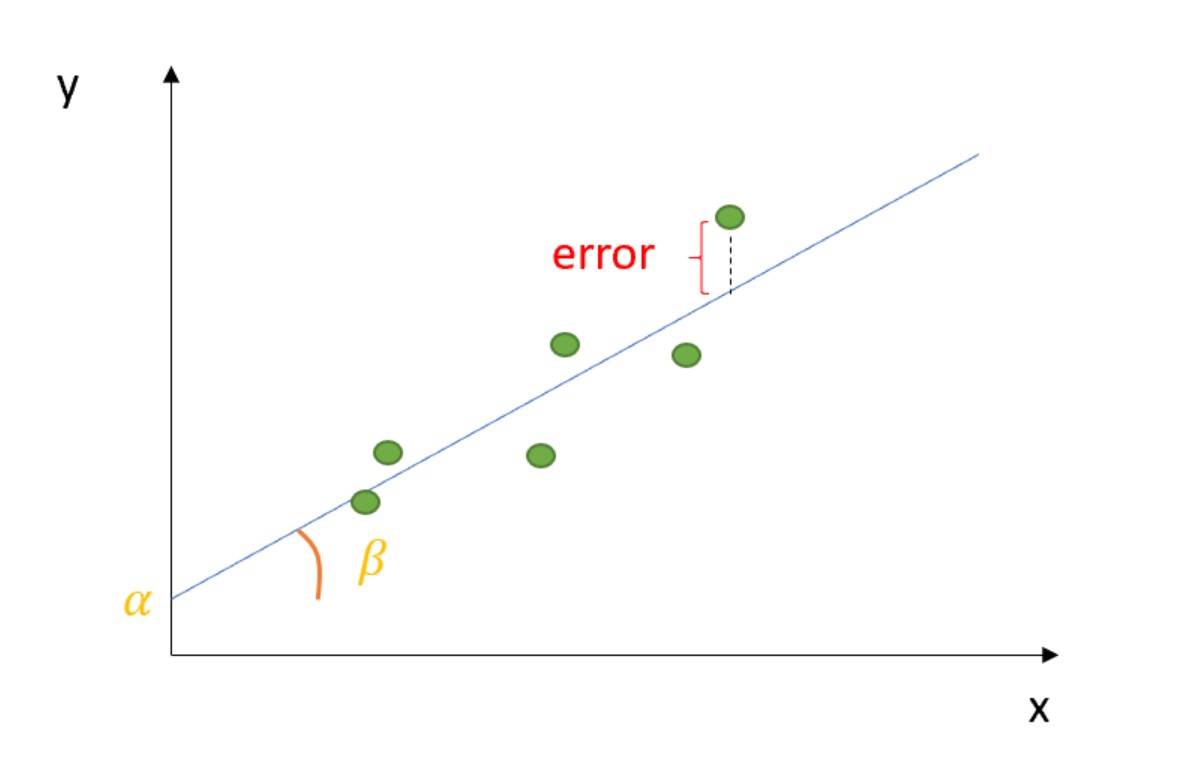
With multiple predictors, each coefficient is a partial derivative — the effect of one variable holding all others constant. This is the foundation of causal reasoning in regression: what changes when we change just this one thing?
Move to logistic regression, and things get more subtle. The log-odds space is linear, but the probability space is not. The coefficients no longer translate directly to probability changes because the sigmoid function is non-linear. To talk about effects on probabilities, you need marginal effects — which are themselves just derivatives of the predicted probability with respect to each predictor, estimated via finite differences (I wrote more about this here).
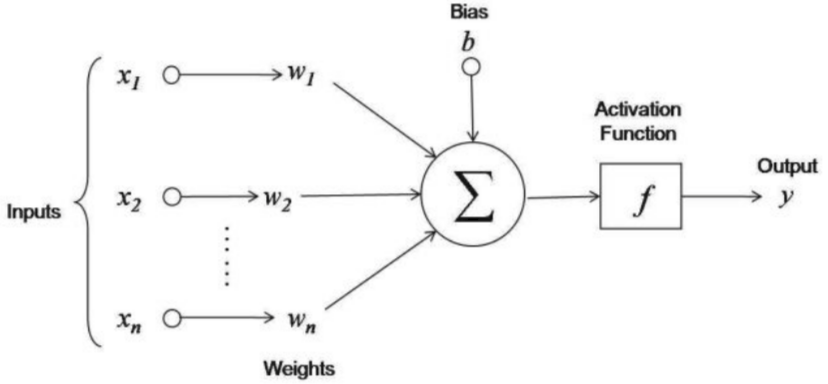
Neural networks are the same story. Strip away the complexity and a neural network is a stack of linear transformations with non-linear activations in between. The whole training process is just gradient descent — iteratively updating weights by following the derivative of the loss function. Understanding derivatives means understanding why networks learn at all.
2-Probability & Uncertainty
Every time I introduce probability and uncertainty to students, I can see the moment it lands: when they realize these aren’t two separate things, but one idea expressed two ways.

Probability quantifies likelihood. Uncertainty is what we have when we don’t know the outcome. Probability is the tool we use to represent and reason about uncertainty numerically.
Here’s the deeper insight: a probability encodes what we don’t know about reality. If we knew with certainty that an event would happen, we’d assign it probability 1. The entire range between 0 and 1 is the space of our ignorance, structured. Probability theory is the rigorous framework for navigating that space.
This matters practically because every model you build is making predictions under uncertainty, and the way you represent and communicate that uncertainty shapes the decisions people make based on your output. A model that returns a single number is hiding information. A model that returns a distribution is being honest.
3-Deployment
Here’s a scenario I’ve seen play out: you’ve received an interesting dataset, you’ve spent a week building a model that could genuinely save the client serious money, the validation metrics look great, and then you realize that one of the key variables you used in training isn’t available in the production environment.
![]()
It sounds obvious in hindsight. It happens constantly. People who are deep in the modeling phase often stop thinking about deployment: what data is actually available at prediction time, what latency the system can tolerate, how the model interfaces with other systems, what happens when the input data doesn’t match training expectations.
Understanding the production environment isn’t optional. The model only does anything useful when it’s running in the real world. Every technical decision — feature selection, preprocessing pipeline, model complexity, output format — should be made with a clear picture of what deployment looks like.
The question was about three things, but I can’t leave out a fourth.
4-Spaces
In machine learning, you’re constantly moving between different mathematical spaces: input space, output space, feature space, embedding space, latent space, parameter space. The word “space” is used so frequently that it can start to feel like jargon. But the underlying concept is genuinely important.
The practical insight is this: transforming between spaces often makes problems tractable. In logistic regression, moving from probability space to log-odds space gives you a linear relationship you can fit with standard methods. In neural networks, each layer with an activation function is a non-linear transformation into a new space — one where the data may be more separable, more structured, more useful for the task at hand.
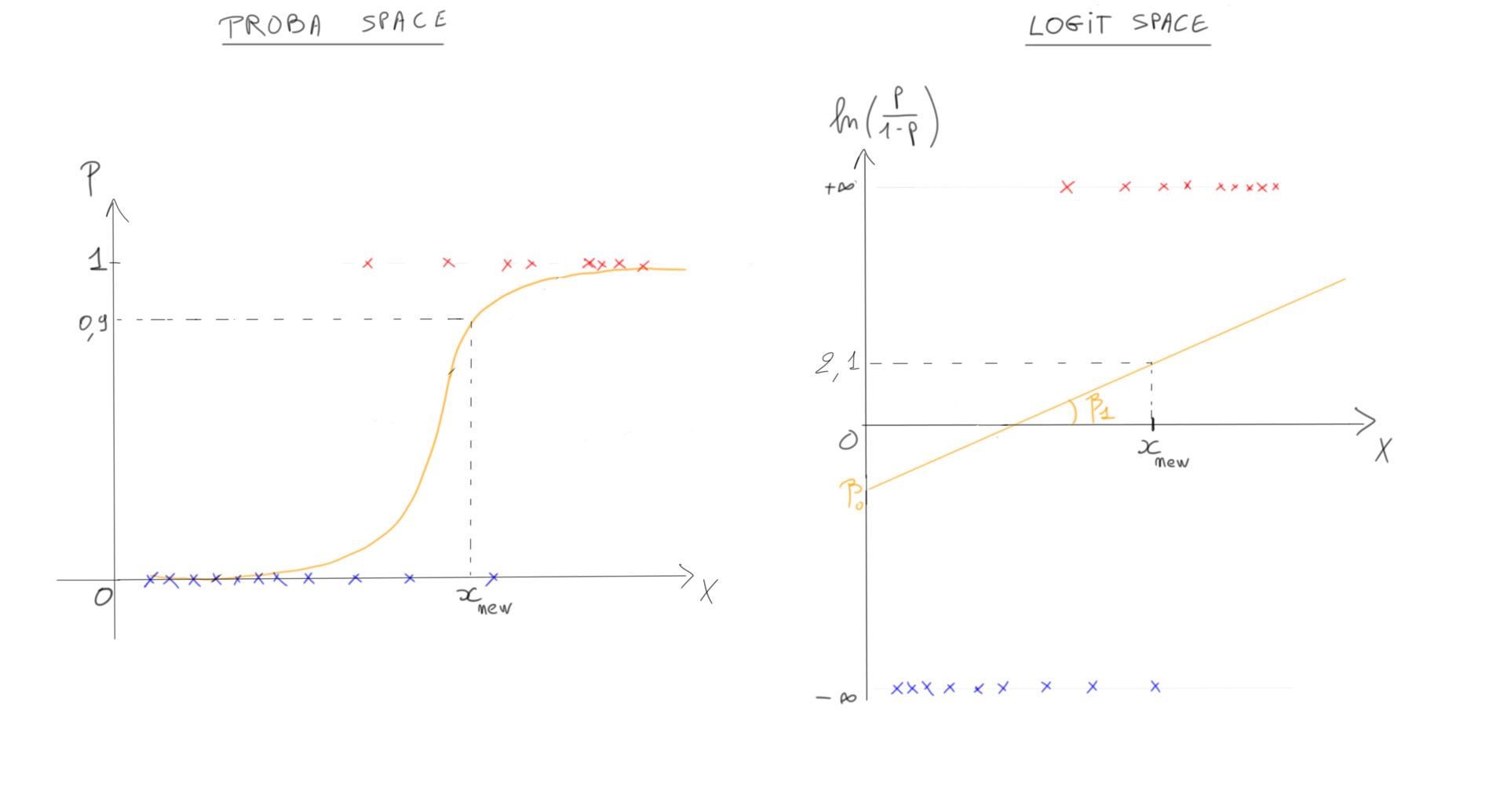
When you understand that operations like activation functions, embeddings, and kernels are all ways of changing the space in which you’re working, a lot of machine learning ideas that seem arbitrary start to make sense. You’re not just applying transformations — you’re looking for spaces where the problem becomes easier.